Long Context Windows Are Not a Memory System
A 10M token context window solves the wrong problem. Here's what it actually can't do.
Real-World Failure
Your team is building a coding assistant. You hear that Gemini now supports 1M token context. The instinct is immediate: just stuff everything in. All previous conversations, all user preferences, all project history. No retrieval, no memory system, no complexity.
Six weeks into production, the cracks appear. Latency is brutal — 8-12 seconds per response on long sessions. Costs are 40x what you projected. The model starts ignoring instructions buried 600k tokens back. Users with short histories get fast, cheap, accurate responses. Power users with long histories get slow, expensive, degraded ones.
You built a context window, not a memory system. The distinction didn't seem important until it was.
Why It Happens Technically
Context windows and memory systems solve fundamentally different problems, and conflating them produces a system that does neither well.
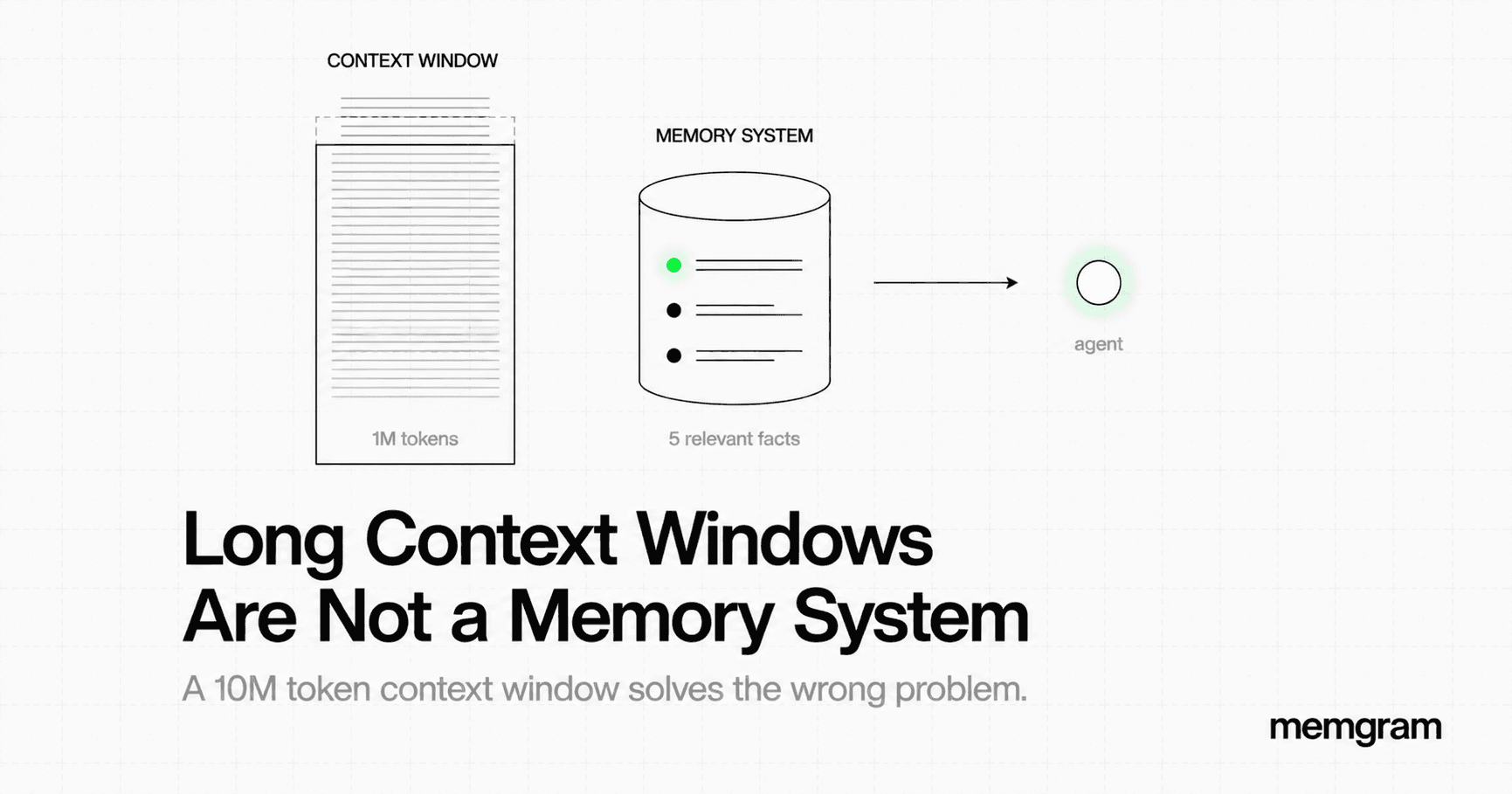
A context window is a working memory primitive. It holds everything the model can attend to in a single forward pass. Larger is better, within limits — but it's bounded by the transformer's attention mechanism, which scales quadratically with sequence length. A 1M token context at inference time means the model is computing attention across 1M tokens for every single token it generates. The compute cost isn't linear — it compounds. This is why latency and cost explode at scale.
There's a deeper problem: attention is not uniform across a context window. Research consistently shows that models attend more strongly to the beginning and end of a context, with significant degradation in the middle — the so-called "lost in the middle" problem, documented in Liu et al. (2023). A fact stored 600k tokens back in a 1M context is not reliably retrievable. It's present, but the model may not effectively use it. Presence in context is not the same as reliable recall.
Memory systems, by contrast, are retrieval primitives. They don't hold everything — they hold what was worth keeping, indexed for fast lookup, with relevance scoring at retrieval time. A memory system with 10,000 stored facts can surface the 5 most relevant ones in under 200ms. A 1M token context holding the same information surfaces everything — relevant or not — at enormous cost.
The architectural difference: context windows are synchronous and stateless across sessions. When the session ends, the context is gone. Memory systems are asynchronous and stateful. They persist across sessions, across users, across agents. These are not competing approaches to the same problem — they're solutions to different problems entirely.
Why Common Approaches Fail
The "just use a bigger context" pattern. Teams delay building a memory system by increasing context size. This works in development where session lengths are short and costs are absorbed. It fails in production where power users generate long histories, costs scale superlinearly, and latency degrades exactly for the users who matter most — the ones who have used the product long enough to accumulate significant context.
The "summarization as memory" pattern. Teams periodically summarize conversation history and inject the summary into context. This reduces token count but introduces a new failure mode: summarization is lossy. The LLM doing the summarization decides what to keep. Specific facts — a user's exact constraint, a precise technical preference — get smoothed into generalities. The summary feels complete but the fidelity of individual memories is degraded. You've built compression, not memory.
The "rolling window" pattern. Teams keep the last N tokens of conversation in context and discard the rest. This controls cost and latency but discards everything outside the window regardless of importance. A critical constraint established in session one is as likely to be discarded as a pleasantry from last week. Recency is not relevance.
All three patterns treat context management as a memory substitute. It isn't. They reduce the problem — they don't solve it.
Mental Model: Context Is RAM, Memory Is Disk
Here's the reframe.
Every computer has two types of storage that serve different purposes:
RAM → fast, expensive, temporary, limited capacity, lost on shutdown
Disk → slower, cheap, persistent, large capacity, survives across sessions
Context windows are RAM. Memory systems are disk. Trying to use RAM as disk — keeping everything in context indefinitely — works until it doesn't, and when it fails it fails expensively.
The analogy extends further than it first appears:
Capacity limits are hard, not soft. You can't exceed RAM by just adding more RAM indefinitely. At some point the economics become prohibitive. The same is true of context windows — 1M tokens sounds like a lot until you're serving 10,000 users with long histories simultaneously.
Speed degrades with load. RAM access is fast when the working set is small. It degrades as the working set grows and thrashing begins. Context window performance degrades similarly — latency and attention quality both suffer as context length increases.
Persistence requires a different layer. When a process ends, RAM is cleared. When a session ends, context is cleared. If you haven't written important state to disk, it's gone. If you haven't persisted important memories to a memory system, they're gone.
What you keep in RAM vs disk is an architectural decision. Good systems are deliberate about what lives where. Current turn context belongs in the context window — it's hot, it's needed immediately, it's transient. User preferences, historical facts, long-term goals belong in memory — they're cold, they need indexing, they need to survive session boundaries.
The practical version of this mental model:
Context window → current session, active reasoning, immediate task context
Memory system → cross-session state, user model, persistent facts, historical decisions
These are not alternatives. They're layers. A production agent needs both, with a clear contract about what belongs in each.
Production Implications
Cost at scale is non-negotiable. A 1M token context at GPT-4 pricing costs roughly \(10-30 per million tokens depending on model. A power user generating 500k tokens of history per month costs \)5-15/month in context alone — before any actual inference for their queries. Multiply by 10,000 users and the economics collapse. Memory systems retrieve 5-10 relevant facts per query at a fraction of that cost. The economics aren't close.
Latency is a product problem, not just an engineering problem. An 8-second response time for users with long histories creates a two-tier experience: new users get fast responses, power users get slow ones. This is exactly backwards. The users who have invested the most in the product — who have the longest history — get the worst experience. This churn signal is hard to diagnose because it looks like a performance issue, not a memory architecture issue.
Cross-session and cross-agent state is architecturally impossible with context alone. Context windows are session-scoped. When the session ends, they're gone. When a user switches devices, starts a new conversation, or interacts with a different agent in your system — the context is gone. A memory system that persists across session boundaries is not an optimization. For any serious production agent, it's a requirement.
Open Problems and Tradeoffs
Context windows are genuinely better for some things. Coherence within a single long session is better with a large context than with retrieval. The model has access to the full reasoning chain, can reference earlier turns precisely, and doesn't suffer from retrieval misses. For single-session use cases — code review, document analysis, long-form writing — large contexts are the right tool. The mistake is assuming they generalize.
Retrieval introduces its own failure modes. A memory system that retrieves the wrong memories is worse than no memory system — it confidently surfaces incorrect context. The retrieval miss rate matters. The importance scoring accuracy matters. The dedup quality matters. These are engineering problems that large context windows sidestep by including everything. Neither approach is strictly better — they have different failure modes.
Hybrid approaches add complexity. The correct architecture for most production agents is a combination: a memory system for persistent cross-session state, and a context window for current session reasoning. This is the right answer but it's a more complex system to build, debug, and maintain than either approach alone. Teams underestimate this complexity consistently.
How Memgram Approaches This
Memgram is the persistent layer that context windows can't be. POST /memory/add extracts and persists what's worth keeping across sessions. POST /memory/search retrieves the 5-10 most relevant memories at query time — not everything, just what matters. The PipelineTrace shows exactly what was extracted, scored, and persisted from each session, so the persistent layer is auditable in a way that a context window never can be.
Context windows handle the present turn. Memgram handles everything the model needs to remember about the user across turns, sessions, and agents. The boundary between them is the precondition for doing anything about either.