You Can Trace Every LLM Call. You Have No Idea What Your Agent Remembers.
Observability for AI systems is almost complete. Memory is the missing layer.

Real-World Failure
A fintech company ships a personal finance agent. Three months in, a user files a complaint: the agent recommended reallocating retirement savings into equities — advice that contradicted the user's explicitly stated risk tolerance from their very first session.
The engineering team pulls the logs. The LLM call is there. The tool invocations are there. The response is there. What isn't there: any record of which memories were retrieved before the response was generated, what the memory system believed about this user's risk profile at that moment, or whether the correct memory was even present in the store.
The trace stops at the LLM boundary. Everything before it — the memory retrieval, the belief state, the extraction decisions from three months of sessions — is invisible. The team cannot answer the user's complaint with evidence. They can only guess.
Why It Happens Technically
Modern AI observability tools — LangSmith, Helicone, Braintrust, Phoenix — are built around a specific mental model of what an AI system does: it receives a prompt, calls an LLM, optionally invokes tools, and returns a response. This model is correct for stateless systems. It is incomplete for systems with memory.
Memory introduces a stateful layer between sessions that existing observability tools don't model. When an agent retrieves memories before generating a response, that retrieval is a reasoning input — as significant as the user's message itself. But it happens outside the LLM call. It's not a tool invocation in the traditional sense. It's a read from a stateful store that shapes everything the LLM subsequently generates.
The result: observability tools capture what the LLM did with its inputs. They don't capture what the memory system decided those inputs should be.
This gap has three distinct components:
Write-side invisibility. When a conversation is processed and memories are extracted, the decisions made — what to store, what to drop, what importance score to assign, what to supersede — are not logged by default. The extraction step is an LLM call making judgment calls, and those judgment calls vanish.
Read-side invisibility. When memories are retrieved for a query, which memories surfaced, what scores they received, and which were considered but not returned — none of this is captured in standard observability pipelines.
Belief state invisibility. At any given moment, what does the memory system believe about a user? This question — the equivalent of "what is the current application state?" in traditional software — has no answer in systems built without memory observability.
Why Common Approaches Fail
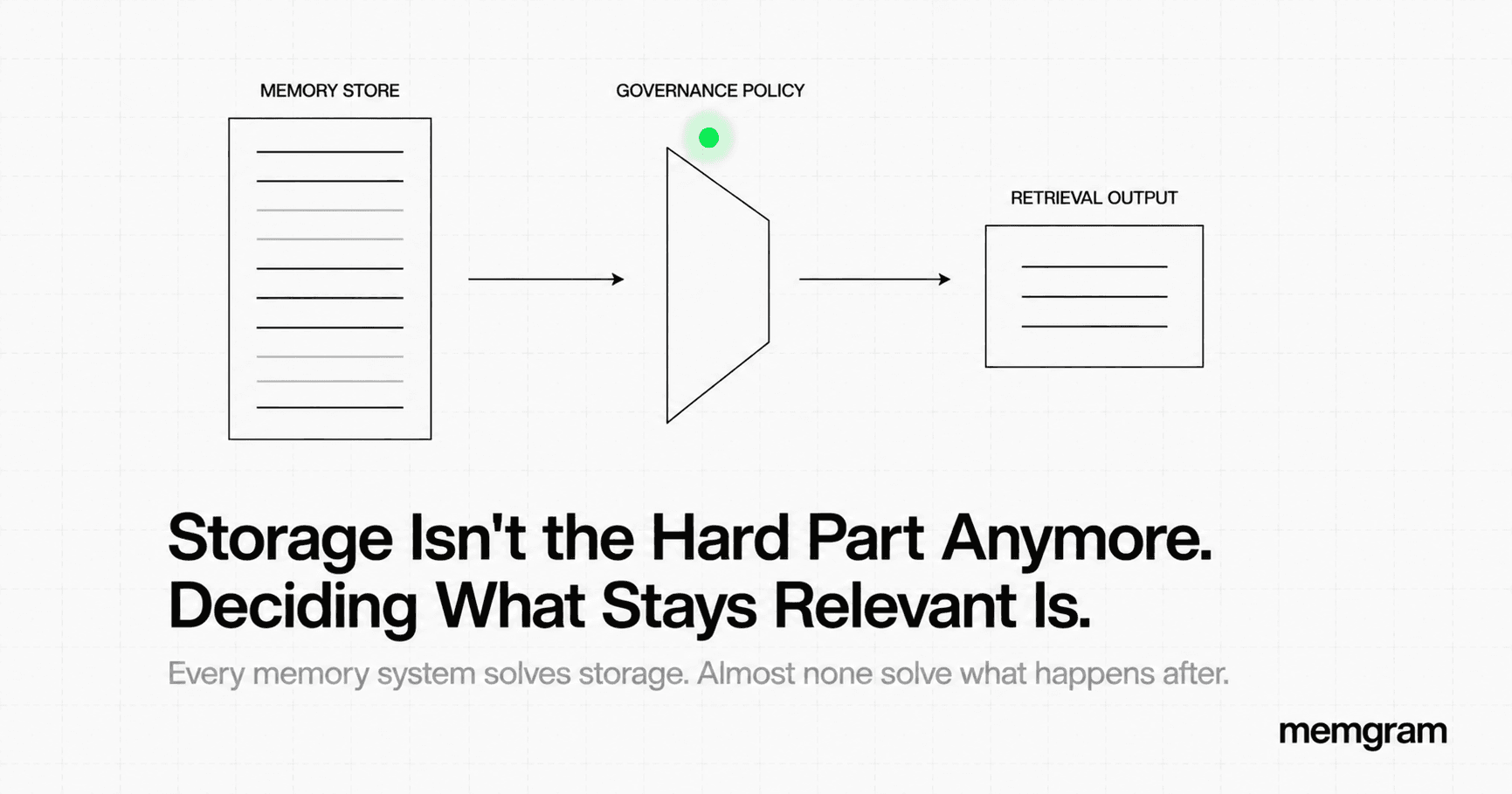
The "log the retrieved memories" pattern. Teams add logging around the memory retrieval call — appending the returned memories to the LLM trace. This captures what was returned but not what was considered and rejected, not the scores, not the retrieval reasoning. It's the equivalent of logging the final database query result without logging the query plan. You see the output, not the decision.
The "add memory to the prompt trace" pattern. Teams inject retrieved memories into the system prompt and rely on LLM observability tools to capture them as part of the prompt. This works partially — the memories are visible in the trace — but it conflates memory state with prompt content. You can't distinguish between what the user said and what the memory system supplied. The provenance is lost.
The "monitor outputs for quality" pattern. Teams use LLM-as-judge evaluations to flag responses that seem off. This catches output quality issues after they've already reached the user. It tells you a response was wrong. It doesn't tell you whether the wrong response came from a bad retrieval, a stale memory, a missed extraction, or a model failure. The evaluation catches the symptom. The cause remains invisible.
All three approaches treat memory as an implementation detail of the prompt construction step. It isn't. It's a first-class reasoning input that deserves first-class observability.
Mental Model: The Observability Stack Has a Missing Layer
Here's the reframe.
Production AI systems have four distinct layers that can fail independently:
INFRASTRUCTURE → latency, uptime, error rates — covered by standard APM tools
LLM CALLS → token counts, costs, response quality — covered by LLM observability tools
AGENT BEHAVIOR → tool use, reasoning chains, task completion — covered by agent tracing tools
MEMORY STATE → what was extracted, what was stored, what was retrieved, what the system believes — covered by almost nobody
The first three layers have mature tooling. The fourth is where the hardest production failures live — and it has almost no tooling.
This isn't an accident. Memory state is harder to observe than LLM calls because it's distributed across time. An LLM call happens in a single moment. Memory state is the accumulated result of every extraction decision across every session a user has ever had. Observing it requires capturing decisions at write time, retrieval time, and query time — and connecting them into a coherent view of how the system's belief about a user evolved.
What full memory observability actually requires:
Write-side tracing. Every extraction run should produce a trace: every candidate considered, its type, its importance score, the dedup decision, the rejection reason if dropped, and the LLM reasoning that produced each decision. This trace should be queryable by session, by user, by agent, and by time.
Read-side tracing. Every retrieval should log which memories were returned, their scores, and which were considered but not returned. The retrieval trace connects the query to the belief state it produced.
Belief state snapshots. At any point in time, it should be possible to ask: what does this memory system currently believe about this user? The answer should be a structured, queryable view — not a reconstruction from logs.
Causal linkage. The write trace, read trace, and belief state should be linkable — so when a response goes wrong, you can trace backward from the output through the retrieval to the extraction decisions that produced the retrieved memories.
Without all four, you have partial observability. Partial observability in a stateful system is often worse than none — it creates false confidence that you understand what's happening.
Production Implications
Debugging wrong agent behavior. When an agent gives a wrong answer, the first question is always: was this a model failure or a memory failure? Without memory observability, you cannot answer that question. You replay the conversation, guess at what the memory system might have retrieved, and form a hypothesis you can't verify. With extraction and retrieval traces, the answer is a lookup: here is what was retrieved, here is what was stored, here is the decision that produced it.
Compliance and audit requirements. Regulated industries — healthcare, finance, legal — increasingly require explainability for AI decisions. "The model generated this response" is not an explanation. "The model generated this response based on these retrieved memories, which were extracted from these sessions, with these importance scores" is. Memory observability is the difference between an AI system that can be audited and one that cannot.
Detecting extraction drift. Extraction quality isn't static. As conversation patterns change, as users interact differently, as context lengths grow — the extraction LLM's decisions shift. Without write-side tracing, this drift is invisible until it produces visible failures. With extraction traces, you can monitor importance score distributions, rejection rates, and classification accuracy over time and catch drift before it compounds.
Open Problems and Tradeoffs
Tracing adds latency and cost. Full write-side and read-side tracing means more data written per operation. For high-volume production systems processing thousands of memory operations per second, the overhead is real. Teams have to make deliberate choices about trace retention, sampling rates, and storage costs. Full fidelity tracing for every user indefinitely is not free.
Belief state is a snapshot, not a truth. A belief state snapshot shows what the memory system believes — not what is actually true about the user. These diverge, sometimes significantly, as discussed in the temporal memory problem. Observability makes the belief state visible. It doesn't make it correct. Teams sometimes conflate the two.
Causal linkage is architecturally hard. Connecting a specific retrieved memory to a specific agent response requires maintaining trace IDs across the retrieval call, the prompt construction, and the LLM call. This requires instrumentation at multiple layers and coordination between the memory system and the LLM observability tooling. Most teams don't have this plumbing. Building it is non-trivial.
Retrieval-to-response tracing is still an open problem. Write-side tracing is tractable. Connecting a specific retrieval to a specific LLM inference and response — the full causal chain — requires the memory system and inference layer to share a trace context. This is an area where tooling is still immature across the industry.
How Memgram Approaches This
Memgram is built around the write-side trace as a first-class primitive. Every POST /memory/add produces a PipelineTrace — every candidate considered, its importance score, dedup decision, rejection reason, and full LLM reasoning text. Dropped candidates are logged alongside persisted ones. The trace is queryable via GET /trace/:id.
The read side logs query text and result memory IDs via search logs — so you can see what was retrieved for a given query, even if connecting that retrieval to a specific LLM response still requires manual correlation.
The write-side decisions are visible. The belief state is auditable. What the system decided to remember — and why — is the precondition for doing anything about it.