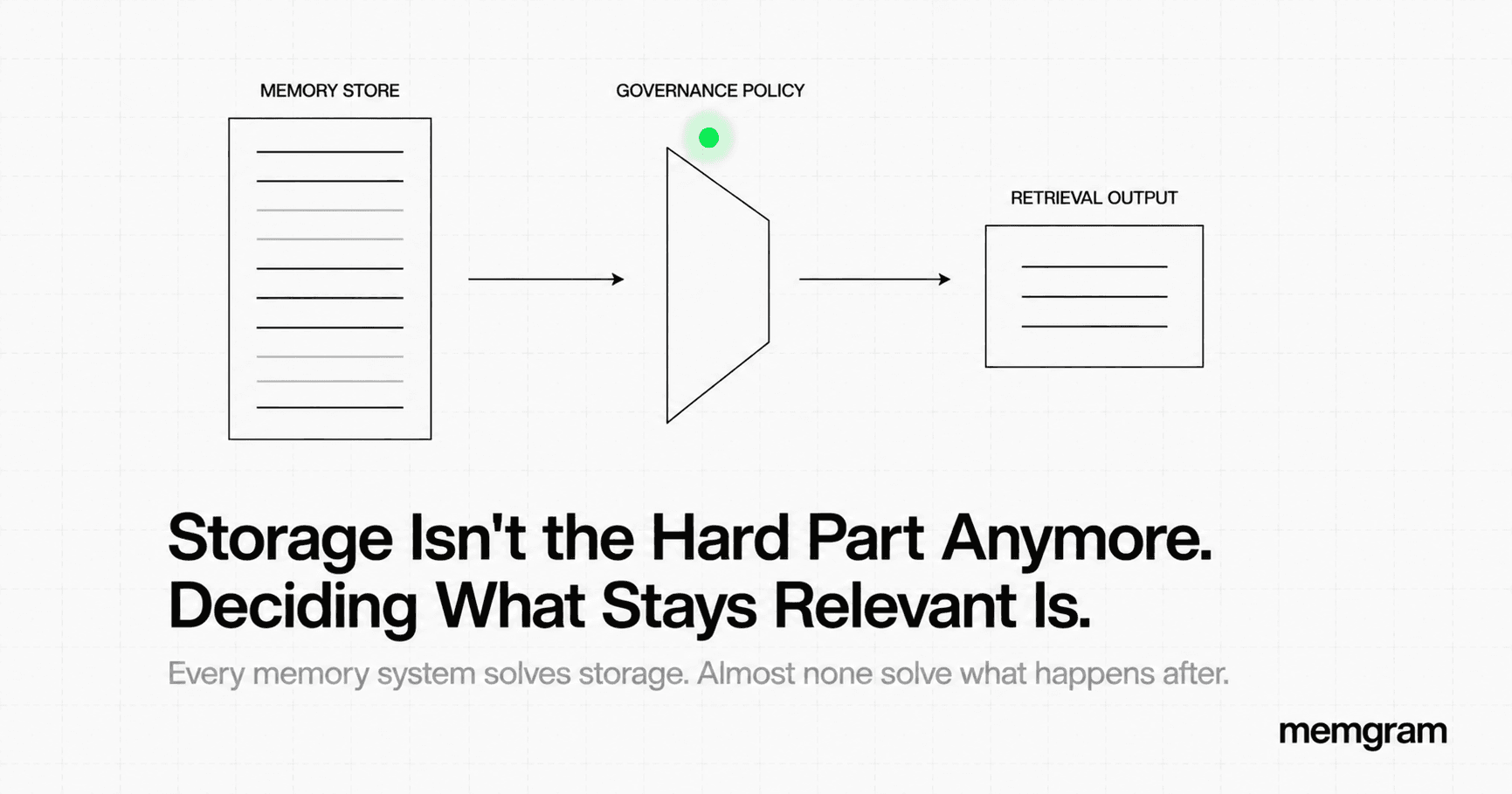
Knowledge Graphs and Vector Memory Are Not Competing. You're Just Using Both Wrong
Why the real question isn't which one to choose, but which facts belong in which store.
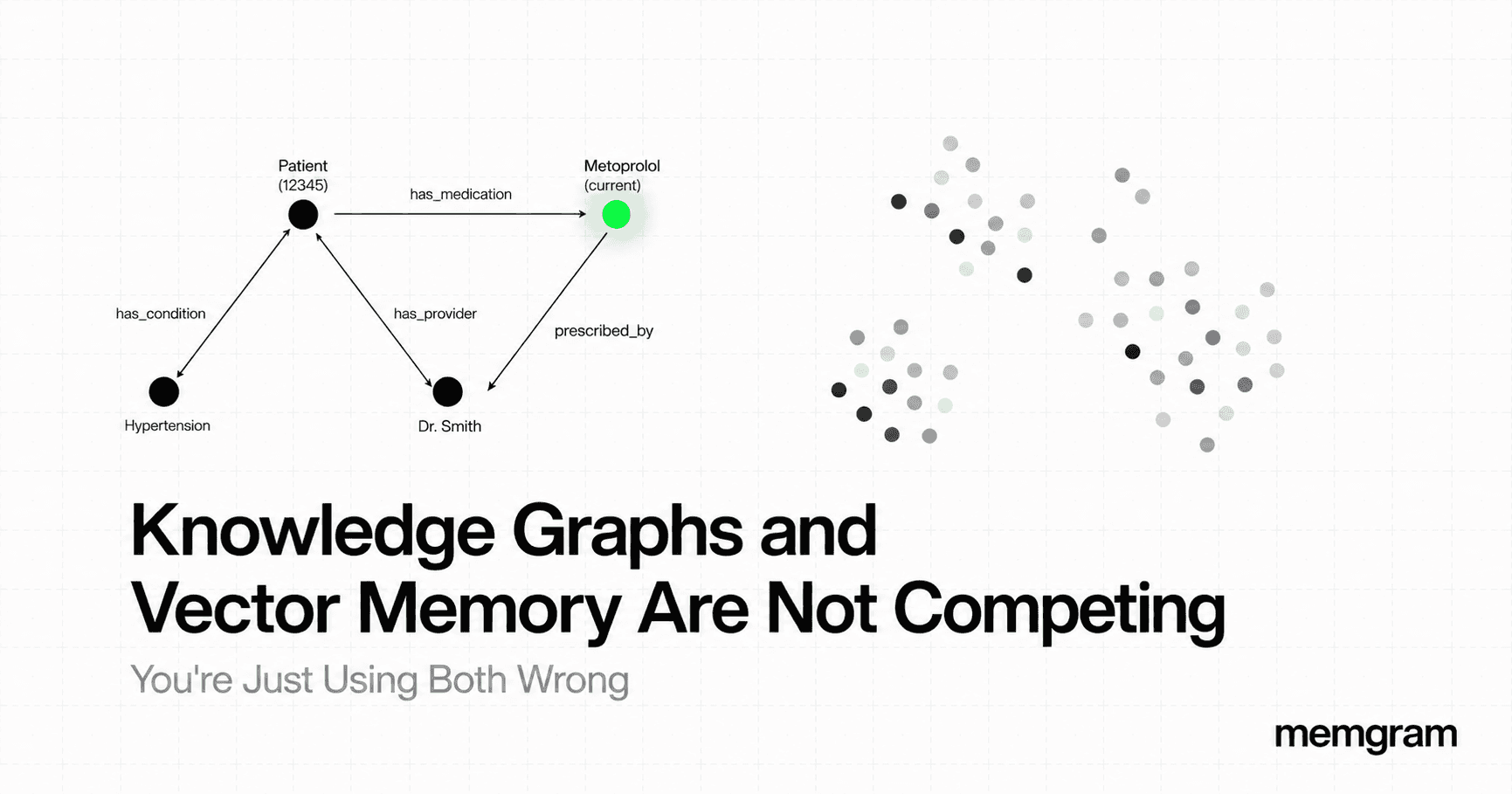
Real-World Failure
Your agent is a healthcare onboarding assistant. During intake, a patient mentions they're on 10mg of Lisinopril for blood pressure. Three months later they tell the agent their cardiologist switched them to Metoprolol.
Your vector store now has both. "Patient takes Lisinopril" and "Patient takes Metoprolol" are semantically similar. Same domain, same patient, same context. Both surface on retrieval. Your agent, depending on which scores higher that session, gives medication interaction guidance based on the wrong drug.
Nobody catches it in QA. It surfaces when a patient flags it.
Simpler but equally common: a customer support agent for a SaaS product. User downgrades from Enterprise to Starter in session four. Your agent references Enterprise-tier features in session nine, because both plan states are sitting in the vector store with nearly identical embeddings and retrieval is non-deterministic.
Both failures share the same root. The system stored a fact with exactly one current correct value using a store that has no concept of "current."
Why It Happens
Technically Vector similarity search is a retrieval primitive optimized for relevance, not for truth.
When you embed "Patient takes Lisinopril" and "Patient takes Metoprolol" and store both, their cosine similarity is high. Same patient, same medical domain, same grammatical structure. A retrieval query for "patient's current medication" surfaces both. The vector store has no concept of superseding. It has no concept of a fact having a single current value. It stores embeddings and returns the closest ones. Full stop.
This works well for a specific class of information such as preferences, opinions, experiences, context etc where multiple values can legitimately coexist. "User prefers concise responses" and "user asked for more detail on technical topics" are both simultaneously true. Vector retrieval handles this correctly because there's no conflict to detect.
But current medication, job title, location, employer, plan tier, account status etc are facts with exactly one correct value at any given moment. The previous value isn't an alternative, it's wrong. Storing both and retrieving by similarity treats them as equally valid candidates.
The technical root: vector stores are stateless about the relationship between embeddings. They don't know that embedding A supersedes embedding B. They don't know that A and B describe the same attribute of the same entity. They know cosine distance. That's a retrieval primitive, not a knowledge primitive.
Knowledge graphs are stateful about relationships by design. A node represents an entity. An edge represents a typed relationship. "Metoprolol" superseding "Lisinopril" for the same patient node is a graph update, the old edge is marked inactive, the new one is written. The graph enforces single-value semantics for predicates that require it. The vector store cannot, because enforcing semantics was never its job.
Why Common Approaches Fail
Two failure patterns that appear repeatedly in production:
The "vector for everything" pattern. Teams start with a vector store because setup is fast and unstructured content works well. They add dedup logic, usually cosine similarity thresholding, to prevent near-duplicates. This catches obvious redundancy but misses semantic superseding. "Patient takes Lisinopril" and "Patient takes Metoprolol" don't score similar enough to trigger the dedup threshold, so both persist. The dedup logic was designed for redundancy, not for single-value fact enforcement. These are categorically different problems, and conflating them is where the architecture breaks.
The "graph for everything" pattern. Teams go the other direction and force all memory into a knowledge graph. Preferences, sentiments, observations, and context are all modeled as typed edges. The graph becomes a thicket because these information types don't fit the entity-relation-object model cleanly. "User seemed frustrated during the onboarding call" is not a graph edge. Forcing it into one creates brittle schema, sparse nodes, and retrieval logic that requires graph traversal for queries that would be trivial with vector search.
Both patterns fail for the same underlying reason: they apply one retrieval primitive to two categorically different types of information. The failure isn't in the technology — it's in the assumption that one store can handle both categories well.
Mental Model: Facts Have Cardinality
Here's the reframe that changes how to think about this.
Every piece of information an agent stores has an implicit cardinality. The number of values that can simultaneously be true for a given attribute of a given entity.
Cardinality-one facts: current medication, job title, location, employer, plan tier, account status, preferred language. At any moment, exactly one value is correct. Previous values are superseded and not archived alternatives.
Cardinality-many facts: preferences, opinions, experiences, skills, goals, context. Multiple values can simultaneously be true. "Prefers dark mode" and "prefers concise responses" coexist without conflict. "Had a bad onboarding experience" and "found the API docs helpful" are both valid and both matter.
The storage decision follows directly:
Cardinality-one → Knowledge graph | Single current value per predicate per entity | Old values marked superseded, never deleted | Conflict detection is a graph lookup, not a guess
Cardinality-many → Vector store | Multiple embeddings per semantic domain | Retrieval by similarity | No conflict to detect
This reframe collapses the "graph vs vector" debate into one question: what is the cardinality of this fact?
The answer tells you where it goes. You don't choose an architecture upfront. You classify your data and let the classification decide the routing.
In practice this means the extraction pipeline needs a classification step and not just "what type is this memory" but "does this attribute admit multiple simultaneous values or exactly one?" That's a different question than most extraction pipelines ask, and it's the question that determines whether conflict detection will work at all.
One additional implication worth sitting with: temporal history is free when you use this model correctly. Old values in the graph are never deleted, rather marked is_current: false with a superseded_at timestamp. You get a full audit trail of how facts changed over time at zero additional engineering cost. A patient's full medication history, a user's plan history, an account's status history: all there, all queryable, without building anything extra.
Production Implications
Healthcare and regulated data. "What medication was this patient on during session seven?" is a compliance question, not just a product question. With a graph that preserves superseded values with timestamps, that query is a deterministic lookup. With a vector store accumulating embeddings, you're reconstructing history from similarity scores and timestamps on embeddings — which is archaeology, not auditing. One of these survives a compliance review.
Customer support at scale. A support agent referencing the wrong plan tier isn't a minor UX issue — it creates false expectations, incorrect billing guidance, and support escalations. When cardinality-one facts are graph-routed, the agent's answer to "what plan is this user on" is always deterministic. There's no retrieval variance. The bug surface for an entire class of support failures goes to zero.
Debugging contradictory behavior. When an agent references a stale fact, the first debugging question is: which memory was retrieved? In a hybrid system with proper cardinality routing, cardinality-one facts are always current by definition and the graph enforces it. The stale retrieval can only be coming from the vector layer. That cuts the debugging surface in half before you've looked at a single log.
Open Problems and Tradeoffs
Cardinality classification is itself an LLM call. Deciding whether a piece of extracted information is cardinality-one or cardinality-many requires semantic understanding and that classification can be wrong. A miscategorized cardinality-one fact routed to the vector store brings back the original problem. Extraction instructions help significantly, but edge cases persist and there's no clean automated solution yet.
Semantic contradiction across cardinality-many facts is unsolved. "Loves my job" from session five and "thinking about quitting" from session forty are both cardinality-many and sentiments can coexist. But they're in tension. The graph doesn't capture this because they're not the same predicate. The vector store doesn't capture this because it doesn't model relationships between embeddings. A fitness coaching agent accumulating hundreds of contradictory motivation signals, or a healthcare agent seeing conflicting emotional states across sessions. These are real production problems the field hasn't converged on yet.
Graph schema rigidity. Typed edges require upfront decisions about which predicates exist. Novel attributes that appear in production require schema updates. Vector stores handle unexpected information gracefully. Graphs require maintenance. This tradeoff is manageable but real.
Practical Recommendations
Add a cardinality classification step to extraction. Before routing a memory to storage, answer one question: can multiple values of this attribute simultaneously be true for this entity? Yes → vector. No → graph. This single decision eliminates the most common class of memory conflict and requires no architectural overhaul — just a classification in the extraction prompt.
Use entity-relation-object triples strictly for graph facts. The triple structure enforces discipline. If you can't express a memory as subject → predicate → object with a single correct value, it doesn't belong in the graph. This constraint is what keeps the graph clean.
Never delete superseded graph values. Mark them is_current: false with a superseded_at timestamp. Storage cost is negligible. Temporal auditability is invaluable — especially in regulated environments where "what did the system know at time T" is a real question.
Route cardinality-one queries directly to the graph. Don't run similarity search for current medication, current plan, or current role. The answer is deterministic. Treat it that way and remove an entire class of retrieval variance from your system.
Write extraction instructions that name the predicate. Vague extraction produces vague classification. Instructions that explicitly name expected predicates — "extract current employer as a cardinality-one fact" — produce dramatically more reliable routing than instructions that describe memory types abstractly.
How memgram Approaches This
Memgram routes at extraction time based on memory type. Structured facts, cardinality-one by definition, go to the knowledge graph as typed entity-relation-object edges. Current medication, plan tier, location: exactly one current value per user, per predicate. When a new value arrives, the old edge is marked superseded_at. It's never deleted. Conflict detection is a graph lookup.
Everything else routes to the vector store and is compared semantically. The PipelineTrace records which path each candidate took and why. So when a routing decision is wrong, it's visible.
The cardinality boundary isn't always clean. But making it explicit is the precondition for doing anything about it.