The Moment Memory Starts Guessing, It Stops Being Memory
Why the boundary between memory and reasoning is the most important line you're not drawing in your agent architecture.

Real-World Failure
Your agent handles customer onboarding. A user mentioned three months ago that they were evaluating your product for a healthcare team. They never said they completed the evaluation. They never said they bought. They never said they're still in healthcare.
Your memory system stored: "User works in healthcare."
Six months later the user asks a billing question. Your agent responds with HIPAA-compliant data handling assurances — unsolicited, confident, specific.
The user is now at a fintech startup. They switched jobs two months ago. They find the response confusing, slightly alarming, and they lose trust in the agent.
Nobody touched the memory. The system didn't malfunction. It remembered correctly — and then reasoned beyond what it remembered. That's the failure.
Why It Happens Technically
The root cause is architectural, not a bug in any single component.
When an agent retrieves memories and passes them to an LLM for response generation, the LLM doesn't treat memories as a bounded dataset. It treats them as context — and LLMs are trained to be maximally helpful with context. They fill gaps. They infer. They extrapolate. That's what they're optimized to do.
So when the memory layer returns "User works in healthcare" and the LLM encounters a billing question, it doesn't ask "is this fact still current?" It asks "how can I use this fact to give the best answer?" Those are fundamentally different questions.
The problem compounds because memory retrieval is similarity-based. A billing question retrieves the healthcare fact because they're contextually related — compliance, regulation, data handling. The retrieval is working correctly. The LLM's use of it is working correctly. The failure lives in the space between them: there is no contract about what the LLM is allowed to do with a retrieved memory.
In database terms: you'd never let application code mutate a value it only has read access to. But when an LLM reasons over a retrieved memory and presents an inference as if it were a stored fact, that's exactly what's happening — the LLM is writing to the user's mental model using data it was only supposed to read.
There's no type system for memory. No constraint that says: this is a stored fact, not an inference license.
Why Common Approaches Fail
The typical response to this problem is prompt engineering. Teams add instructions like: "Only use retrieved memories as context, do not infer beyond them." This helps at the margins. It does not solve the problem.
Three specific failure patterns that persist even with careful prompting:
The confident inference pattern. The LLM retrieves a preference — "user prefers concise responses" — and infers that the user is an expert who doesn't need explanation. The memory stored a style preference. The LLM promoted it to a capability assumption. The instruction said "don't infer beyond memories" but the LLM's inference happened implicitly, inside the response generation, not as a visible reasoning step.
The stale fact problem. Memory systems store what was true at extraction time. They don't store expiry signals. A memory that was accurate six months ago is retrieved with the same confidence score as one stored yesterday. The LLM has no way to distinguish between them. Prompting it to "be cautious about old memories" requires it to know which memories are old — which it doesn't, because that metadata isn't surfaced.
The aggregation problem. Individual memories are accurate. The LLM aggregates them into a composite picture that was never stored. "User is in healthcare" + "user is cost-sensitive" + "user asked about compliance" becomes "This is a regulated enterprise buyer." Each memory is real. The composite is an inference. The agent acts on the composite.
Prompt instructions operate on the output. The failure is happening during generation, before the output exists.
Mental Model: Memory Is a Read-Only Ledger, Not a Reasoning Surface
Here's the reframe.
Memory and reasoning are two different systems that share an interface and the failure happens when that interface is undefined.
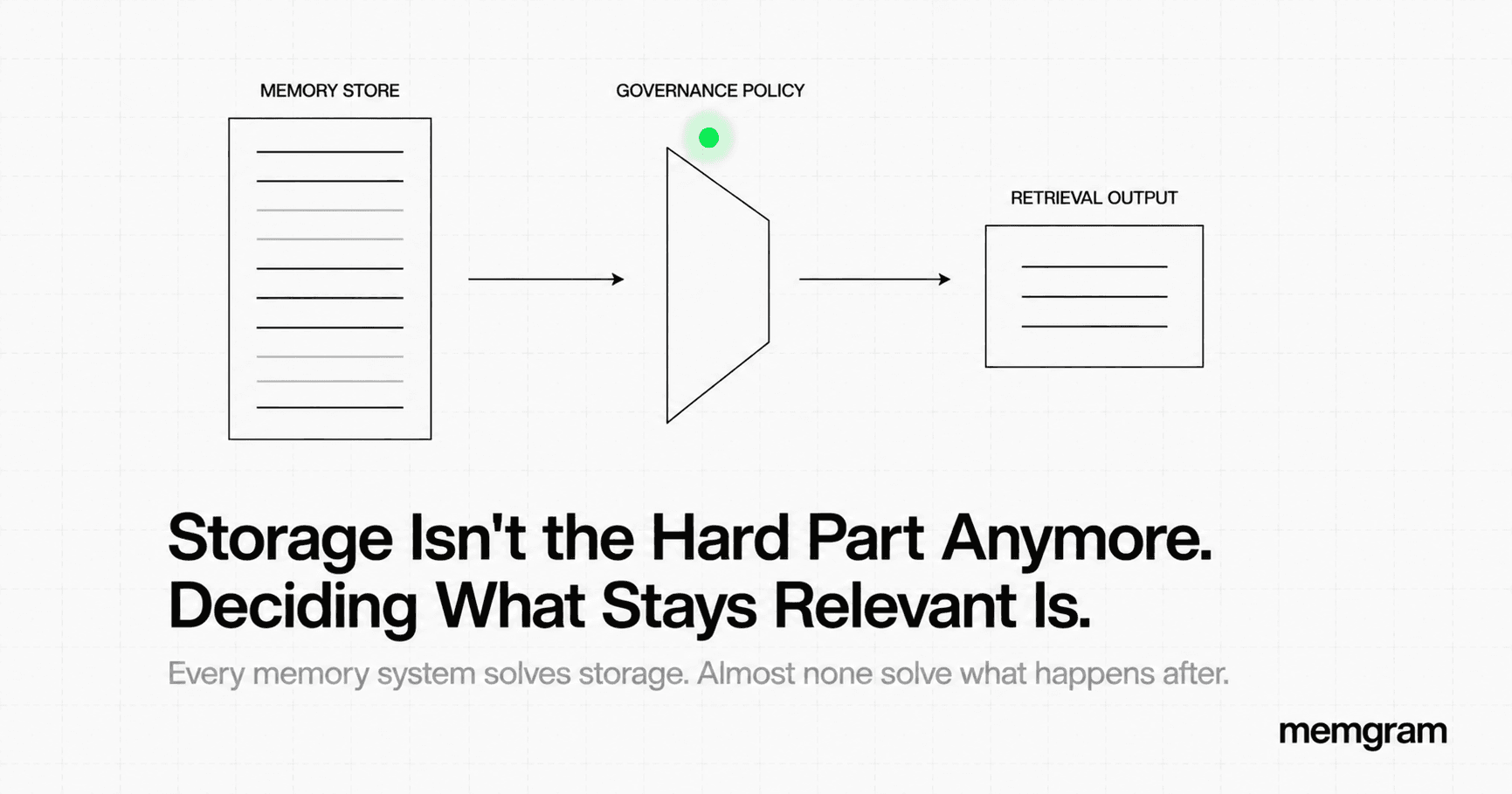
Think of memory as a read-only ledger. It contains entries. Each entry has a timestamp, a confidence score, and a type. The ledger doesn't interpret entries. It doesn't fill gaps between entries. It doesn't project forward from entries. It returns exactly what was written, with full provenance.
Reasoning is a separate process that operates over ledger entries. It can infer. It can aggregate. It can project. But it should be explicitly labeled as doing so — and those inferences should never be fed back into the ledger as if they were stored facts.
The problem in most agent architectures is that this boundary is implicit. The memory system returns facts. The LLM generates a response. The user sees a confident statement. There's no visible handoff between "this is what was stored" and "this is what the LLM inferred from what was stored." Here's the practical version of this model:
Memory layer → returns: fact, type, timestamp, confidence contract: "this was observed"
Reasoning layer → operates on: memory outputs contract: "this is inferred" constraint: inferences are labeled, not persisted as facts
Once you draw this line, two things become clear: First, retrieval and generation need different trust levels. A retrieved memory is an observation. A generated response is an interpretation. The agent's output should distinguish between them — "Based on what I know about you" vs "I'm inferring that" — not blend them into a single confident statement.
Second, the memory system's job is to be a perfect witness, not a helpful advisor. It should return exactly what happened, with exactly the confidence it deserves, and get out of the way. The moment the memory layer starts smoothing, interpolating, or filling gaps — it has crossed from memory into reasoning, and you've lost the boundary entirely.
Production Implications
This boundary failure shows up in three specific ways in production:
Trust erosion over time. Users don't notice one wrong inference. They notice a pattern of the agent seeming to know things it shouldn't, or being confidently wrong about things that changed. That pattern — not any single failure — is what kills user trust in AI agents. By the time the pattern is visible, dozens of bad inferences have already been presented as facts.
Debugging becomes impossible. When a user reports that the agent said something wrong, the first question is: was this stored, or was this inferred? Without a hard boundary and explicit labeling, you cannot answer that question from logs alone. You have to replay the conversation and reconstruct what the LLM likely inferred — which is guesswork.
RAG systems have this problem at scale. Retrieval-augmented generation is the standard architecture. But RAG doesn't enforce the memory/reasoning boundary — it retrieves documents and lets the LLM reason freely over them. In a customer-facing agent where retrieved context includes user history, that free reasoning is a liability. Every response is a blend of retrieval and inference with no label distinguishing them.
Open Problems and Tradeoffs
The memory/reasoning boundary is easy to define conceptually. It's genuinely hard to enforce in practice.
Inference is useful. An agent that only returns stored facts without inference is less helpful. Users want the agent to connect dots. The question isn't whether inference should happen — it's whether it should be labeled and whether it should be persisted. Deciding exactly where helpfulness ends and hallucination risk begins is not a solved problem.
Temporal validity is unsolved at scale. Knowing that a memory is stale requires either an expiry signal at write time (which requires predicting at extraction time how long a fact will be valid — often impossible) or a freshness check at retrieval time (which requires knowing the current state of the world to compare against). Neither is clean.
Composite inferences are invisible. The aggregation problem described above is the hardest to solve. Individual memories are correct. The composite the LLM builds from them is an emergent inference that was never explicitly generated, logged, or auditable. There's no clean architectural answer to this yet — it requires either constraining the LLM's reasoning scope (expensive, imperfect) or logging intermediate reasoning steps (adds latency, complexity).
Practical Recommendations
Explicitly type your memories at write time. Every stored memory should carry a type that signals its certainty and expected lifespan — observed_fact, stated_preference, inferred_context, temporal_fact. The type should gate how the LLM is permitted to use it at retrieval time.
Surface timestamps to the LLM. Don't just retrieve the memory content — retrieve it with its age. "User works in healthcare (stored 6 months ago)" is a meaningfully different input than "User works in healthcare." Let the LLM reason about staleness rather than treating all memories as equally current.
Label inferences in responses. Build response generation prompts that explicitly distinguish between stored facts and inferences. "Based on stored information: X. Based on inference from that: Y." Users deserve to know the difference. More importantly, your logs need to capture it.
Never persist LLM inferences back into the memory store. This is the most critical rule. If the LLM infers something during response generation, that inference should not be written back as a memory. Only observations — things explicitly stated or demonstrated — belong in the ledger.
Audit your retrieval-to-response path. Build tooling that lets you trace: what memories were retrieved, what the LLM was given, what it returned. That trace is the only way to catch boundary violations in production before they accumulate into trust failures.
How Memgram Approaches This
The memory/reasoning boundary is why Memgram stores explicit memory types — fact, preference, goal, skill, event, context, constraint — for every stored candidate. Each memory carries its type, importance score, and timestamp through the full pipeline. When you query via POST /memory/search, you get typed results with provenance, not a blended context blob.
The PipelineTrace captures what was extracted and why — so when your pipeline produces an unexpected output, you can audit exactly what was extracted, what was scored, and what was persisted — the write side is fully visible. The retrieval side logs which memory IDs were returned for a given query via the search logs, though connecting that retrieval to a specific LLM response is still a manual step. The boundary is visible. Which is the precondition for enforcing it.